1000公里
从去年6月份开始重启跑步,到现在,跑龄已经1年4个月了
突然发现,今年累计跑量已超过1000公里
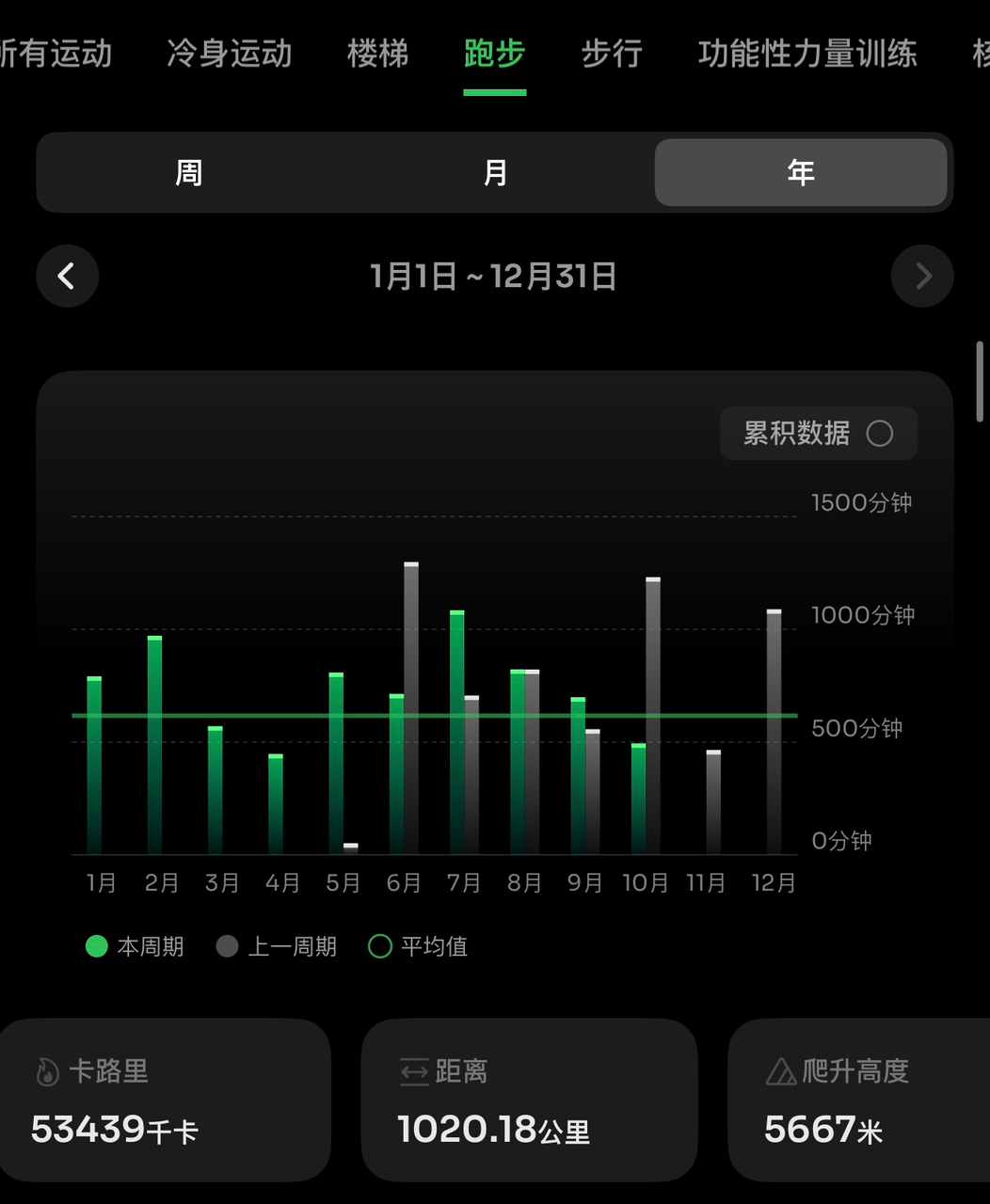
这是第一次年跑步公里数超过这样的水平,对我个人,是一个非常大的突破
跑步已经深度融入到日常生活中
对我而言,跑步的好处实在太多,除了生理上、心理上带来的各种积极变化与帮助,还有一个非常的作用
在跑步的过程中,对自我的认识、能力边界认知、欲望管理,也有不一样的促进
尤其是当我以第三方视角审视自己的时候,那种豁然开朗也经常让人惊喜
在漫长的跑步过程中,人是最容易进入自我对话、自我觉察状态的。没有外界干扰,只有自己的呼吸、步伐和思绪
跑步时,人仿佛既是运动的执行者,又能跳出来以旁观者的角度看待自己。这种视角转换能力,对自我认知有着独特的促进作用
跑步的意义,对我来说,获得的不仅是健康的身体,也获得了一种审视生命、理解自我的新方式
经营资产
对经营公司而言,如果从风险视角,最重要的洞察:经营公司,就是经营风险
但如果从发展视角,目前最重要的洞察之一,应该就是:经营公司,就是经营资产
如何理解这里的“资产”?
资产是指能带来未来经济利益的任何资源,简单说,就是能为自己“赚钱”或“省钱”的东西,满足任意一项都算
它的关键特征包括,可被控制、可衡量、能带来未来收益
所以,对企业或个人创业者来说,资产 = 能持续产生现金流、复利效应或战略壁垒的资源
具体包括:
- 内容资产,比如文章、视频、脚本、知识库
- 技术资产,比如代码、模型、API、架构、专业体系
- 品牌资产,比如声誉、影响力
- 关系资产,比如客户群、合作伙伴
- 系统资产,比如标准化流程、自动化工具
- 金融资产,比如股票、基金、不动产、公司股份
以上,既适用于公司,也适用于个人
个人的资产布局,随着年龄的增长,重要性要越来越大,而且,什么时候开始重视,都来得及,这是因为,绝大多数人,都并不是很重视个人资产的经营
Vibe Coding
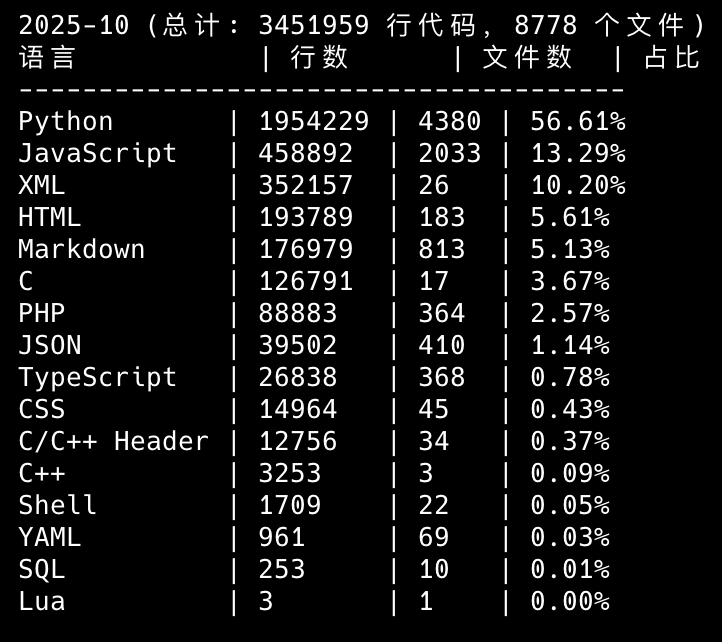
10月份的8天假期,主要是待着媳妇的老家,一个风景优美的北京郊区,主要的活动包括:捡板栗、跑步、写书、开发工具
其中,大部分的时间,都在写工具
因为AI编程能力的大幅提升,作为一个非程序员,这几个月借助Vibe Coding,其编程能力也在快速的提升
10月份这不到10天的时间,写的代码行数超过了345万行,初步完成了4个工具,其中有一个工具的复杂度,也不小,光是梳理它的产品逻辑与需求说明,就花了差不多一下午的时间
这给国庆节的假期,增添了不少乐趣与成就感
在借助AI写工具的过程中,其实也是学习AI编程的过程,通过这样的实战方式,对Vibe Coding也有了很多与之前不一样的理解
在这个过程中,其实最大的挑战,不再是写代码,而是标准的确定
每一个功能逻辑、每一个样式、每一个工具,如何评价它是好是坏?如何将脑子里面对“好”的认知与想象,通过清晰的提示词或工程规划让AI真正的理解并正确执行,这是一个很大的挑战
归根到底,又回归到了对审美、对逻辑甚至哲学层面的认知,回归到了价值观与方向选择,回归到了对用户、对行业的商业洞察
关于增长
如何正确的做增长?
真正的增长,不仅仅是把人拉进来,更重要的是,让人忍不住“回到这里”
世界上顶级的产品,成功的一个共性,就是有着非常好的留存
所以,对产品增长来说,留存,才是真正的杠杆
留存在某种程度上也代表了真正的价值创造
没有留存的产品,即便新增做得再好,也总有枯竭的一天,生命力极其脆弱
做好留存的两个核心底层原则:系统性的增长实验+有效经验的系统复用
关于增长实验,从整体来看,单点实验的效果稳定性是很差的,非常依赖人的经验及运气,而系统性的增长实验逻辑,在于把方方面面的可能性进行全面的梳理,并通过并行测试的方法,拿到大量的数据
通过这种方式,可以快速获得很多有价值的洞察
基于这个逻辑,一个完整的增长体系,应该包括
- 从价值维度,产品必须能持续创造价值,让人忍不住“回到这里”或忍不住“继续合作”,这需要深入理解用户需求,打造核心竞争力
- 从方法维度,通过系统化实验获取数据洞察,而不仅仅靠直觉
- 从规模维度,将成功经验标准化、模块化并大规模复制
- 从时间维度,真正的增长是一个循环往复、不断迭代的过程
GEO与SEO
- 无论SEO还是GEO,决定能否被AI引用的首要因素之一,还是内容质量
- GEO是内容营销的一种新形态,是顺应AI检索与生成的整合式内容营销策略
- 问题驱动替代关键词驱动:SEO围绕“关键词”,GEO围绕“用户完整问题”,这背后搜索行为变化的原因,也是因为AI对复杂语义的处理能力大大增强
- 结构化可以让AI更“省算力”:清晰的分段、列表、数据表与JSON结构化标记更易被AI拆解与引用
- AI倾向选择专业、权威、可验证来源,比如:引用权威研究、标准文档、官方数据,并清晰标注出处
- 信息增益是GEO差异化的一个关键策略,在低成本生成时代,独特洞见与深度实证更稀缺。比如,可以给出实测数据、反直觉结论、失败教训与可复现实验
- 由于AI搜索的“零点击”特点,决定GEO的效果会更偏品牌,用户常在AI答案处结束,一般不点链接,除非有进一步需求,这个时候往往会去检索品牌词;所以,核心价值会体现为“被看见”,即便点击流量不高,但AI频繁提到你的品牌,心智影响会大大提升
- SEO是GEO的地基之一,传统搜索排名在很大程度上会影响AI检索与引用概率
- 品牌的内容,成为训练语料需要较长时间且不可控,对GEO来说,实时搜索是核心主战场,被纳入基础训练门槛极高,现实路径是做SEO提升被实时检索
- 多模态是趋势,短期文本内容的建设和优化性价比最高,可以逐步构建多模态内容体系
- 国内AI幻觉多与搜索服务能力与成本有关,模型常粗略聚合摘要,这样也容易出错,我们曾实验过GEO霸屏的效果,就是利用这种“漏洞”
- 近期做了一个关于AI摘要的GEO实验,最终数据发现,AI摘要对AI搜索的权重影响比想象的要大
关于AI搜索
这一期“未来硅世界”邀请了小宿科技的两位技术专家进行与AI搜索有关的分享,很多干货,通过GPT-5对直播的主要问题进行了梳理:
Q1:AI搜索到底是什么?和百度、谷歌有什么不同?
传统搜索靠关键词匹配,你得自己从10个网页里找答案
AI搜索则是“问题导向型”搜索——你问一句,AI自动整合信息并直接回答
举例:
-
你搜“苹果CEO是谁”,百度列出网页
-
你问AI搜索,它直接告诉你“蒂姆·库克”,并解释他的任期与相关新闻
AI搜索的关键区别是:它不仅找信息,还理解问题并生成答案
Q2:AI搜索要靠“Infra”,这是什么?
Infra是“基础设施”的意思
如果把AI搜索比作大脑,Infra就是神经系统和工具库
它包括:
-
搜索引擎API
-
链接正文提取、PDF解析、网页渲染
-
数据召回、排序、缓存、语义理解模块
这些组件让AI能像人一样“读网页”“理解语境”“引用来源”
Q3:开发者和普通用户使用AI搜索的区别是什么?
-
开发者:关心“如何让我的AI会搜索”,可加入小宿科技开发群,申请API调用额度,拿到技术文档
-
普通用户:只想“得到更聪明的回答”,可直接用AI搜索应用或在活动中提问
一句话:开发者造轮子,用户开车
Q4:为什么要区分ToC搜索和ToAI搜索?
这两种搜索服务的“对象”完全不同
-
ToC搜索:给人看的,返回简短摘要
-
ToAI搜索:给AI读的,返回全文或结构化数据
举个例子:
百度给你“华为发布新机”摘要
而ToAI搜索会给AI整篇新闻稿,让AI能生成一篇分析稿
AI要的不是标题党,而是“可被机器理解的内容”
Q5:从提问到回答,AI搜索内部经历了什么?
- 理解问题:判断是否联网
- 问题拆解:把复杂问题分成多个子问题
- 外部搜索:通过API抓取网页或数据
- 召回排序:筛选最相关内容
- 生成答案:模型整合信息、生成自然语言回答
这像是一支“AI搜索小分队”:模型当大脑,工具当手脚
Q6:AI不是看摘要就够了吗?为什么要全文?
因为AI要“理解语义逻辑”,不是“浏览关键信息”
摘要只能给出结论,AI要根据上下文判断因果、细节、出处
就像人类写论文必须看原文,AI回答问题也要有“上下文依据”
Q7:小宿科技的搜索技术相比其他公司有什么特别?
-
多语种支持:唯一国内支持多语种搜索的厂商
-
纯自研:拥有从爬虫、索引、召回到语义模型的全链路自研能力
-
低延迟:平均响应仅数百毫秒
-
灵活服务:可同时支持AI问答类和智能体类客户
Q8:AI怎么判断“苹果”是水果还是品牌?
靠语义理解模型
AI会分析上下文,识别你的意图,然后决定召回哪类数据
这涉及:
-
意图识别
-
切词与消歧
-
语义匹配
例如你问“苹果市值多少”,系统就会自动切换到“Apple Inc.”的财经数据语料
Q9:AI搜索会不会老是读到旧数据?
不会
一般系统会判断问题是否有时效性
-
非时效性问题(如“地球半径”)可从缓存读取
-
时效性问题(如“今天A股涨跌”)则调用最新索引
甚至在排序模型中,还会给“时效性结果”额外加权,让它们排在更前面
Q10:网页那么多,AI怎么找到“最合适”的那几篇?
通过语义匹配 + 关键词匹配的混合策略
-
语义匹配帮助AI理解上下文
-
关键词匹配保证命中具体词汇
此外,召回分两阶段:
- 离线阶段:过滤不良网页,仅保留优质内容
- 在线阶段:根据query动态排序、再筛一轮
最终留下的往往不到10%,但质量最高
Q11:互联网充满AI写的文章,怎么看?
AI生成内容不是坏事,但要有质量
系统会评估段落逻辑、事实准确性和原创性
低价值的AI洗稿、拼接文会被剔除
一句话:AI创作没问题,关键是得写得“对”
Q12:AI能分辨好文章吗?
能
模型会学习人类的判断逻辑,比如:
-
信息密度高
-
逻辑结构清晰
-
来源可信
-
不抄袭、不空洞
-
系统会将这些特征量化,综合打分,从而识别“高价值内容”
Q13:怎么应对黑帽SEO?
我们有独立反作弊团队
在离线阶段就会剔除黑帽页面、虚假内容和采集站
具体算法保密,但目标明确:让AI搜索生态干净可信
Q14:AI搜索会不会出现不合规内容?
不会
公司在中国的业务遵循国家法律与价值导向
海外则依据当地法律
不同地区使用不同API与数据部署,确保“各地合法,各自合规”
Q15:现在AI搜索的盈利模式是什么?未来会变吗?
目前以API收费为主
未来可能与AI应用合作形成广告或知识付费模式,但不会像百度那样直接插广告
因为ToAI搜索是“B端基础设施”,不是“C端流量入口”
Q16:AI搜索能不能看到全网热词趋势?
目前还没有这个功能
但如果开发者或企业客户有需求,小宿科技可基于搜索数据生成类似“AI趋势榜”“智能体热门问题榜”等产品
关键是:搜索热度由需求驱动,不是噱头驱动
Q17:AI搜索会不会爬取小红书、抖音这些平台?
不会违规抓取
公司严格遵守平台数据政策,只与愿意合作的优质内容方建立数据通道
郭耕良提到:“我们宁愿少,也要干净”
同时,团队也在与垂类厂商谈判,获取更多结构化内容授权
Q18:AI搜索的使用比例有多高?会不会取代传统搜索?
以目前数据看,大约30% 的AI问答会调用联网搜索
随着模型更懂上下文,这个比例还会继续上升
但完全取代百度或谷歌暂时不现实——AI搜索更像“新层”,不是“替代层”
Q19:有了AI记忆功能,它还会继续查网页吗?
会
-
对于固定知识(如物理常数、历史事实),AI可以记忆
-
但对动态信息(如天气、股市、政策)仍需外部更新
-
搜索和记忆是互补的关系
-
未来AI会在“内部知识”和“外部实时数据”之间动态平衡