The Second Half of AI
A blog post by OpenAI researcher Yao Shunyu:
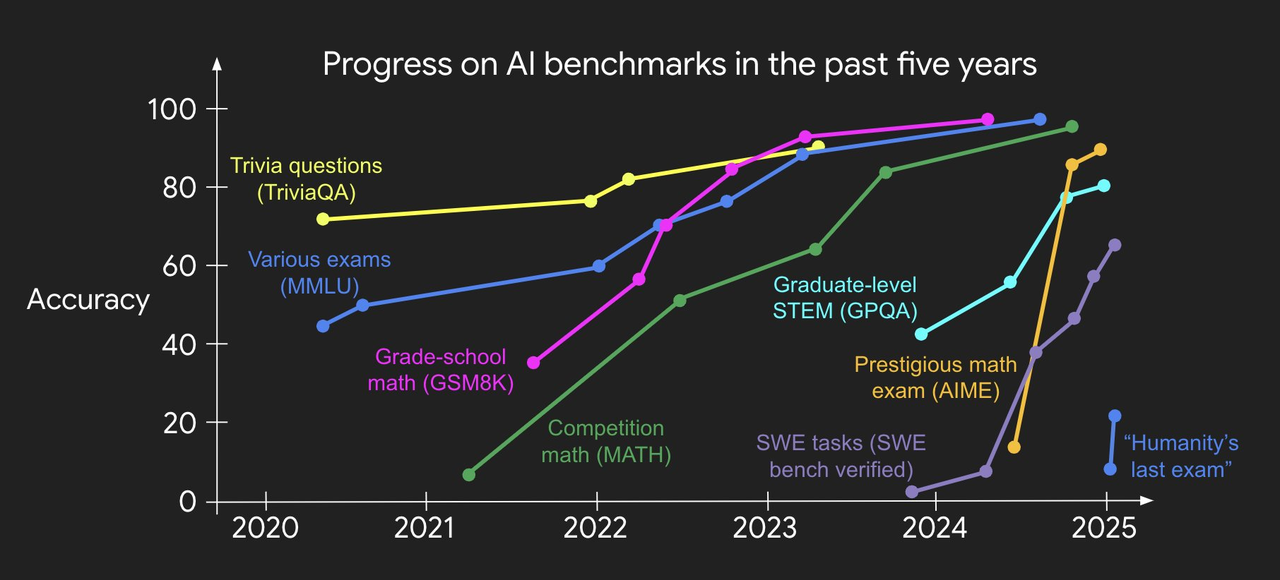
This chart tells us: the traditional “leaderboard race” is winding down. AI models’ lead on standardized benchmarks is rapidly converging toward perfect scores.
More concretely:
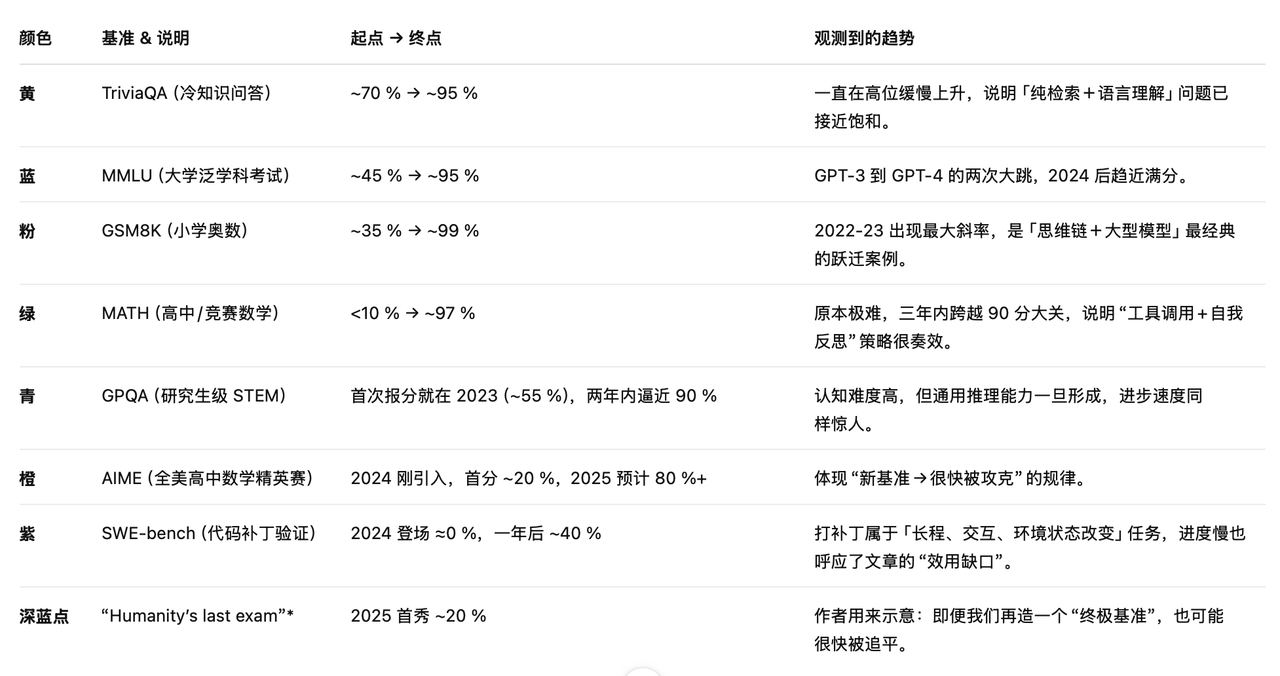
Conclusion: AI has entered “halftime.”
What comes next is a new phase.
In this second half, the rules of the game change entirely: the hard problem is no longer whether we can train a model that solves a given task—but rather what we should ask AI to do, and how to measure real progress.
Though AI has already surpassed top humans on benchmarks like Go, the SAT, bar exams, and even the International Olympiads (IOI/IMO), its impact on GDP or real-world productivity remains limited. That gap is the defining challenge of this moment.
Whoever redefines evaluation—by breaking old assumptions and measuring authentic value—stands to catalyze the next $10B or $1T company.
Meanwhile, incremental 5%-level improvements on legacy benchmarks are increasingly vulnerable to “dimensional strikes” from next-generation o-series models.
In the second half, we must redefine how we measure AI’s value—not by substitution, but by creation.
We need to identify use cases that genuinely unlock AI’s latent potential—not just map AI onto existing human workflows.
And we must build evaluation frameworks rooted in real application—not standardized tests.
Stronger Models Demand Better Prompts

At Volcano’s recent launch event, they shared this image: The stronger the model, the more critical the prompt.
This aligns precisely with my discussion with Xiang Yang.
The logic is simple: stronger models → broader capability → prompts become the steering wheel.
My reasoning:
- Instruction conflict escalates: As models grow more faithful to instructions, poorly written prompts—containing contradictory directives (“Do A” and “Don’t do A”)—trigger internal inconsistency.
- Potential scales non-linearly: When models were weaker, great vs. average prompts might differ by ~10× in output quality. With frontier models, that gap may widen to 100× or even 1000×—making prompt craftsmanship exponentially more consequential.
- Task complexity rises with ambition: As our goals grow more sophisticated, unstructured prompts drown key signals in noise. Hierarchical, well-organized prompts become essential.
The core insight? Prompt engineering shouldn’t be seen as “tweaking phrasing.” It’s designing intent and constraint—and that role will only deepen.
Long-Tail Returns
ROI = Return / Cost
Two levers: increase return (hard), or reduce cost (always possible).
A friend recently shared a paid-search case:
He spends annually on Baidu ads. This year, he discovered high-performing long-tail traffic—low-competition keywords surfaced via Baidu’s keyword tools and recommendation engine. He bid ¥0.5 per click—orders of magnitude cheaper than head terms costing ¥3–¥15.
For the first time, his Baidu campaigns turned profitable.
It’s a textbook long-tail strategy: modest volume, low cost, solid margin.
Annualized, it adds ~¥1M in net profit.
Small companies should embrace this mindset—avoid red oceans; mine quiet, underpriced demand.
The Halo Effect
A meme circulating online:
Before IPO, investors described Pop Mart’s founder Wang Ning as: “unremarkable education, no formal corporate experience, expressionless, uncharismatic, leading a non-elite team.”
After IPO, every investor praised him as: “calm, reserved, emotionally grounded—exemplifying the ideal consumer entrepreneur.”
Your future rewrites your past.
That’s the halo effect in action.
Just as students admitted to Tsinghua get labeled “focused,” while those who underperform are called “rote memorizers”—the same behavior receives opposite interpretations based solely on outcome.
We retroactively impose causality: success beautifies everything; failure taints everything—even when no causal link exists.
So:
- Don’t over-index on external judgment—it’s inherently unstable.
- Focus relentlessly on doing the work well—not on performing for others.
- Sometimes so-called “weaknesses” are hidden advantages: my childhood preference for solitude, for instance, gave me space to think independently—free from adult expectations.
- And if praise arrives later, stay grounded: external attributions are rarely accurate.
The Gentle Singularity
Core thesis: Sam Altman believes humanity has entered the early stage of a gentle singularity.
The hardest technical work is done. What follows is engineering and scaling: deploying intelligence at scale, reliably and efficiently.
Key timeline predictions:
- 2025: Intelligent agents capable of real cognitive work emerge.
- 2026: Systems begin generating truly novel scientific insights.
- 2027: General-purpose robots enter the physical world.
- 2030: Individual productivity surges—coding, research, and creative work become radically accessible.
Other takeaways:
- AI’s biggest dividend is accelerating science: life quality and longevity gains will dwarf all prior eras.
- “Intelligence + energy” will become abundant. When data centers and robots self-replicate and self-expand, intelligence cost approaches electricity pricing—breaking two ancient bottlenecks: ideas (intelligence) and execution (energy + automation).
- Stronger AI → faster science → stronger AI; robots build robots, data centers build data centers—progress compounds.
- Many jobs vanish—but wealth creation accelerates unprecedentedly. History shows humans quickly invent “seemingly fake yet vital” new roles—and adapt fast to new tools.
- Altman describes OpenAI as a “superintelligence research company,” aiming to make intelligence “too cheap to meter”—and ensuring the singularity arrives smoothly, exponentially, without rupture.
- Over the next decade, AI + robotics will drive explosive tech-economic growth—if alignment is solved first, and superintelligence becomes universally affordable. Only then can benefits and risks both be governed.
Implications for individuals & AI founders:
- Position yourself as a human-AI coupling node: the edge lies in “integrating AI into workflows, and workflows into business”—a major advantage for teams with mature operational contexts.
- Build for engineering and scale, not one-off demos.
- Prioritize data loops over model loops: user data must fuel a flywheel—where AI improves outputs, which generate better data, which further improves AI.
- Altman predicts agent-level cognition by 2025—aim to productize intelligent agents this year or next.
- Watch for—or create—“seemingly fake but essential” new roles: e.g., AI output auditor, prompt engineer.
- Study real-world AI engineering deployments—and find the ones that fit your context.
Multi-Agent Strategies
Anthropic’s team published a report on multi-agent systems: anthropic.com
Their experiments show multi-agent systems excel at breadth-first exploration across parallel, independent lines of inquiry.
Results: Their multi-agent setup outperformed single-agent Claude Opus 4 by 90.2% on internal evaluations.
Even the strongest individual pales next to effective teamwork—AI included.
The team also distilled eight principles for designing agent prompts—highly actionable for builders:
1. Understand the Agent’s Decision Logic
- Idea: Think like the agent—how does it parse tasks, retrieve info, select tools?
- Practice: Simulate execution with dev tools; watch for redundant searches, overly verbose queries, or wrong tool choices.
- Value for founders: Debug agent behavior like code—crucial for diagnosing “why did it fail?”
2. Teach the Orchestrator to Delegate
- Idea: Assign roles like a project manager.
- Practice: In prompts, specify each subtask’s goal, output format, tool, and scope.
- Value: Clear delegation is foundational for complex workflow automation.
3. Match Resources to Task Complexity
- Idea: Simple tasks → fewer agents; complex tasks → more parallel agents.
- Practice: Predefine resource caps in prompts (e.g., max tool calls, agent count).
- Value: Controls token cost and avoids over-engineering.
4. Design Tools Like APIs
- Idea: Clarity > cleverness. Each tool needs precise description, input schema, and expected output.
- Practice: Document rigorously—like an API spec.
- Value: Tool usability directly determines whether agents succeed.
5. Let Agents Self-Optimize
- Idea: Claude can analyze its own failures—and suggest better prompts or tool docs.
- Practice: Feed it failure examples and prompt it to revise instructions.
- Value: Semi-automates prompt iteration—saving engineering time.
6. Search Broad First, Then Deep
- Idea: Scan widely before narrowing focus.
- Practice: Guide agents to start with general keywords, then drill into promising directions.
- Value: Boosts information retrieval accuracy—reducing “no results found.”
7. Think Before Acting
- Idea: Enforce deliberate reasoning before execution.
- Practice: Activate “extended thinking mode”: require intermediate analysis and action plans.
- Value: Critical for multi-step reasoning tasks—raises accuracy.
8. Parallelize Execution
- Idea: Run agents and tools concurrently—not sequentially.
- Practice: Shift to parallel architecture; avoid serial bottlenecks.
- Value: Speeds up research-style tasks by ~90%; dramatically improves UX.
How to Build Habits
A study found: 92% of New Year’s resolutions are abandoned within one month.
Setting goals alone doesn’t solve the core problem.
As James Clear writes: New goals don’t yield new results—new lifestyles do. Lifestyle is a process, not an outcome. So invest energy in shaping better habits—not chasing better outcomes.
Good habits are good lifestyles—and good outcomes follow.
What is a habit?
A behavior repeated enough times to become automatic: repeated, unconscious, low-cost.
It’s not just repetition—it’s biology’s energy-saving protocol. Habits also shape identity and daily existence.
Why good habits matter
They don’t just change what you do—they quietly reshape who you are.
Each 5-minute meditation isn’t just stress relief—it’s a vote for “I am someone who values inner calm.”
Lifestyle is the sum of habits. Repeat them, and you don’t just act differently—you identify differently.
Good habits compound.
Read a few pages daily → substantial knowledge in a year.
Move for 10 minutes daily → measurable health gains over years.
How to build them easily
Use BJ Fogg’s Behavior Model:
Behavior = Motivation × Ability × Prompt
- Motivation: How much you want to do it
- Ability: How easy it is to do
- Prompt: The trigger that reminds you
Behavior occurs only when all three converge above an “action threshold.”

Applying it: Building a reading habit

My practice
Over the past six months, I’ve anchored six daily micro-habits: wake up early, meditate, read/listen, write, run/strength train, study English.
Motivation was relatively easy to sustain. Ability came next—by starting absurdly small. But the real leverage was prompt anchoring:
- Wake up → 6 a.m. watch alarm
- Meditate → right after napping or resting
- Listen to audiobooks → during driving
- Read → right after scheduled “input time”
- Run → immediately after waking
- English → paired with morning coffee
With these anchors, building each micro-habit required almost no willpower.
Philosopher Zeno reflected on his life: “Happiness accumulates in small steps—but it is never simple.”
A recent Feishu note put it well:
You see friends posting gym check-ins, rush to buy a yearly membership—and quit after three days of soreness.
Superficial lesson: “Go slower next time.”
Philosophical lesson: Human action isn’t driven by desire—it’s sustained by inertia. Without a sustainable rhythm or system, even grand ambitions collapse into one-time enthusiasm.
Desire wakes you up. Inertia carries you forward. Lose the latter, and the former is just wind.
May you find profound, self-sustaining change—not in heroic leaps—but in tiny, repeatable motions.