When Agent Numbers Exceed Humans
- In today’s world, an image no longer necessarily proves the truth. An image only proves that there is an image. It does not prove that something actually happened.
- In three to five years, the number of intelligent endpoints that can actually do work may far exceed the number of humans. There may be tens of trillions of intelligent agent devices executing tasks every day and creating a completely different kind of productivity. What will truly change the world is the explosive growth in the number of intelligent terminals that can execute tasks autonomously.
- Agent organizations will combine three collaboration patterns: human to human, human to AI, and AI to AI. The new organizational form of AI-to-AI collaboration may become a mainstream mode of work. Once AI-to-AI collaboration matures, the marginal cost of organization will fall sharply. Many companies may become extremely small organizations made of a few humans and a large number of agents.
The next generation of organizations will no longer be judged only by headcount. The more important question will be: how many high-quality agents can the organization coordinate? I am looking forward to that.
- The wealth gap has always been widening. To some extent, the widening gap is closely tied to technological progress.
- Only after the strongest models cross a certain intelligence threshold will the application ecosystem truly explode, instead of being absorbed by the model layer itself. This may still take another two or three years.
- The more agent devices there are, the more creativity and productivity will be released. Behind this is a hidden demand: marketing will become increasingly important. Positioning, communication, and even how you influence an agent’s judgment will matter. This is essentially GEO.
- Recently, I have met several founders who are extremely candid in private. They do not package or perform. They will say directly that the company is still living on financing and that the business may not work in the short term. But if they can survive until model capability, market demand, and application scenarios mature at the same time, they may get a real chance to turn the situation around.
- Language models have consumed the internet’s text. Robots may next consume human behavior.
The following three images were generated by GPT-image-2:



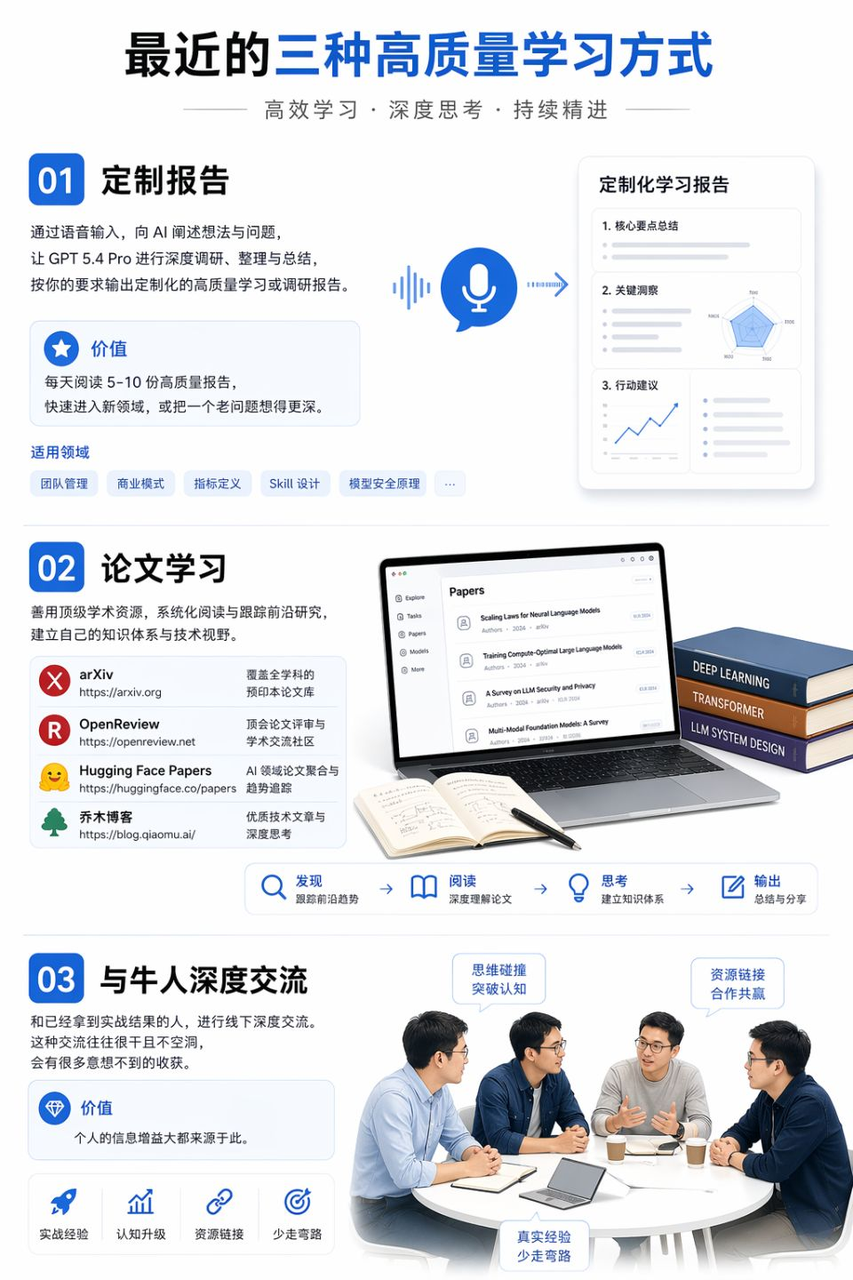
Three High-Quality Ways to Learn
Recently, I have been using three high-quality ways to learn.
- Custom reports
I often have many thoughts and questions during the day. I record them by voice, explain the context to AI, and ask GPT 5.4 Pro to do deep research, organize the material, and produce a high-quality report customized to my questions.
This habit has greatly improved my learning efficiency. Many days, reading five to ten reports like this is enough for me to quickly enter several new domains, or to think more deeply about an old question.
Team management, business models, metric definitions, Skill design, and model safety principles are all good topics for this kind of learning.
- Paper learning
I mainly follow arXiv, OpenReview, and Hugging Face Papers.
I also read Qiaomu’s blog.
- Deep conversations with strong practitioners
Talking offline with people who already have real results is often direct and useful. Those conversations are rarely empty. They often create unexpected information gain.
Much of the truly valuable information I get comes from this kind of exchange.
An Overseas Business Case
Over dinner with several industry experts, I heard a very interesting business case.
It was about a cross-border e-commerce company.
At the time, the team analyzed Japan’s annual trending keywords. One of the terms was “sexual harassment.”
They continued to analyze it and found that the main scenarios were offices and public spaces.
Then they collected a large number of photos and analyzed the profile of people who were being harassed.
They found one common feature: large breasts.
So they designed a product that could be understood as chest protection, or more specifically, something that could make the chest look smaller.
After the product was ready, they seeded a lot of content around topics such as how to prevent sexual harassment in public places, how to protect yourself at work, and small tools or little secrets for preventing harassment.
The product quickly took off. In its first year, one single SKU generated 80 million in revenue.
What this case shows is not just product selection ability. It is the ability to integrate social emotion, trending semantics, scenario demand, and content narrative.
Good Business Communication
A business development colleague from ByteDance added me on WeChat. Several small details were quite good and are worth learning from.
- After I accepted the request, she immediately sent her Feishu profile QR code and explained the background and reason for adding me.
- After I replied, she clearly asked for a phone call to make the first conversation more efficient.
- Before the call, she sent a screenshot of her Feishu profile, including department name, email, and direct manager information.
We then scheduled a short five-minute phone call. It was very efficient. We quickly reached common ground on topics like organizing a small salon and evaluating standards for GEO service providers.
In communication with a new business contact, the first step is to make identity, background, and intention clear. That lowers the other person’s judgment cost. The efficiency and quality of the following conversation become very different.
Bayesian Decision Skill
I open-sourced a Bayesian decision Skill.
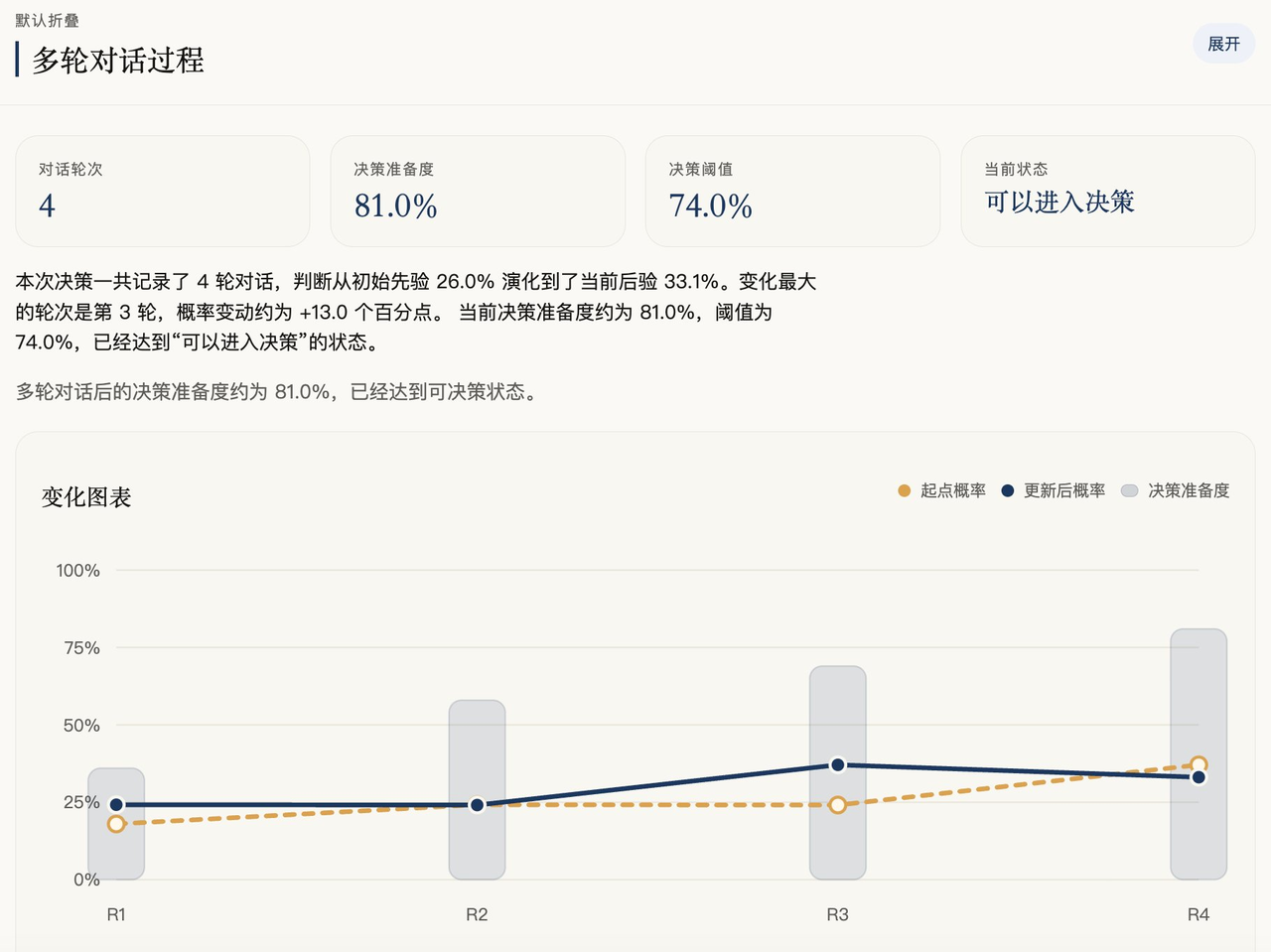
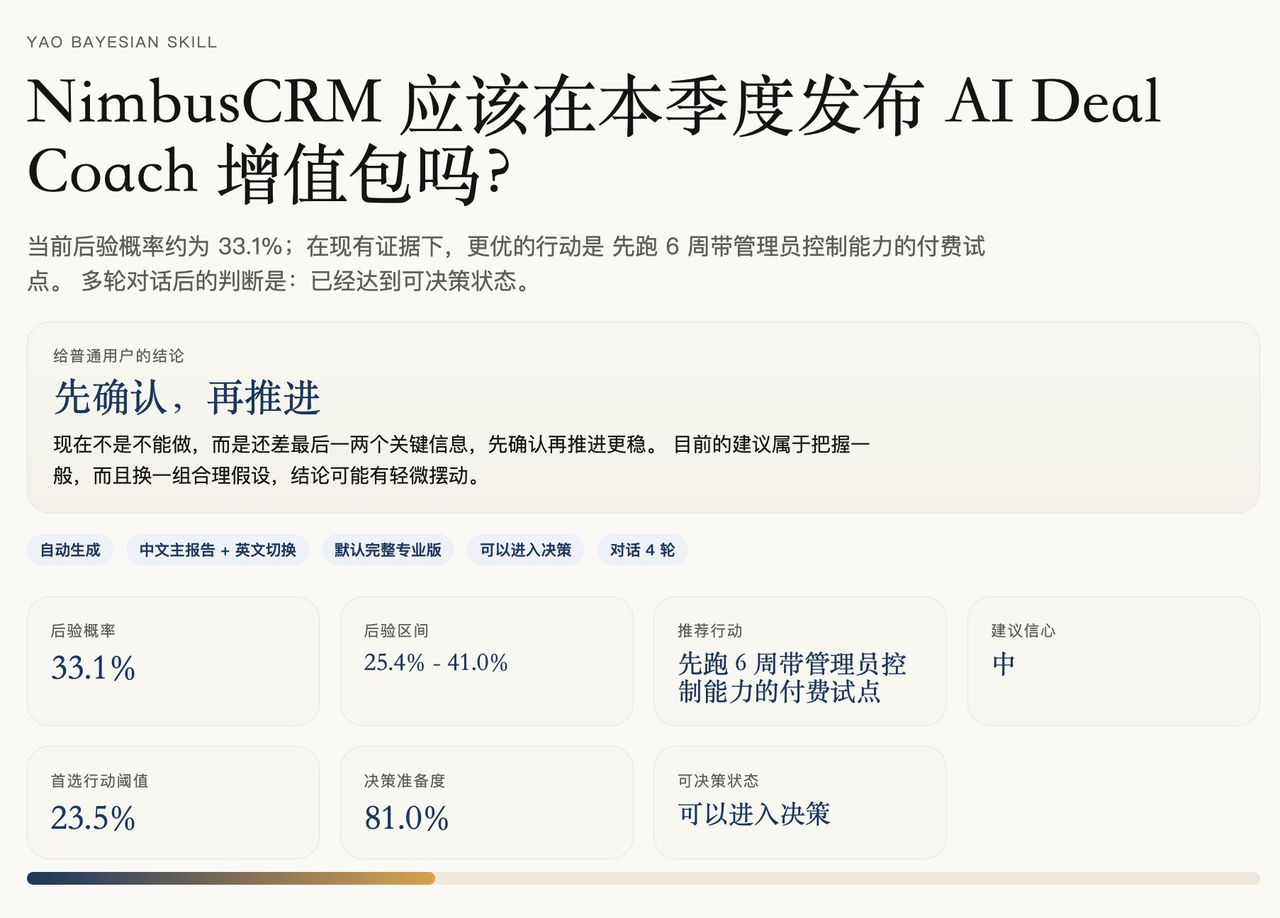
It does not simply calculate a Bayesian formula. It helps turn a complex decision into a process where judgment can be updated continuously.
At the beginning, the Skill forms an initial judgment based on the available information. Then AI guides the user through multiple rounds of conversation, adds variables, updates the posterior judgment, and records why the judgment changed at each step.
Finally, it outputs a Markdown and bilingual HTML decision report, including the conversation process, the changes in judgment, and action recommendations.
It is suitable for product, growth, business, and startup decisions. It is also useful for personal decisions such as travel, moving, or career choices.
In essence, it answers this question: when information is incomplete and risk is uncertain, how can we judge more rationally whether something should be done, and how can we improve the quality of the decision?
GitHub repository: yao-bayesian-skill
This method may not be completely objective in real life. But the process itself raises a person’s rationality score. That may already be a new kind of gain.
The essence is to teach people to look at the world through change. Bayesian thinking does this. Calculus does this too.
One reader commented on the Skill: the Bayesian formula itself is not hard. The hard part is quantifying and clarifying, step by step, the intuitive thoughts that appear in your mind. That work is not glamorous, but it is practical.
The following images are sample reports:


Some general Bayesian prior principles in the Skill:
- I may be wrong, so I should leave room.
- Look at the base rate before the individual story.
- Evidence has different strengths.
- The more surprising the conclusion, the stronger the evidence required.
- One or two cases do not represent the whole.
- To understand people and events, look at incentives.
- Avoid ruinous risk before pursuing upside.
- Missing expected evidence is also information.
- Correlation is only a clue. Causality needs more proof.
- Extreme performance often regresses toward the mean.
- When evidence is similar, prefer the simpler explanation.
- When uncertain, preserve reversible choices.
- Human behavior often has situational logic. Understand before judging.
- Beliefs should have confidence levels, not just yes or no.
- Contradictory evidence improves judgment the most.
- Recent and vivid events are often overestimated.
- Every rule and choice may have side effects.
- Average patterns matter, and individual differences also matter.
- Start with goodwill, then verify gradually and build tiered trust.
- Priors expire and should be recalibrated regularly.
Thinking About Agent Organizations
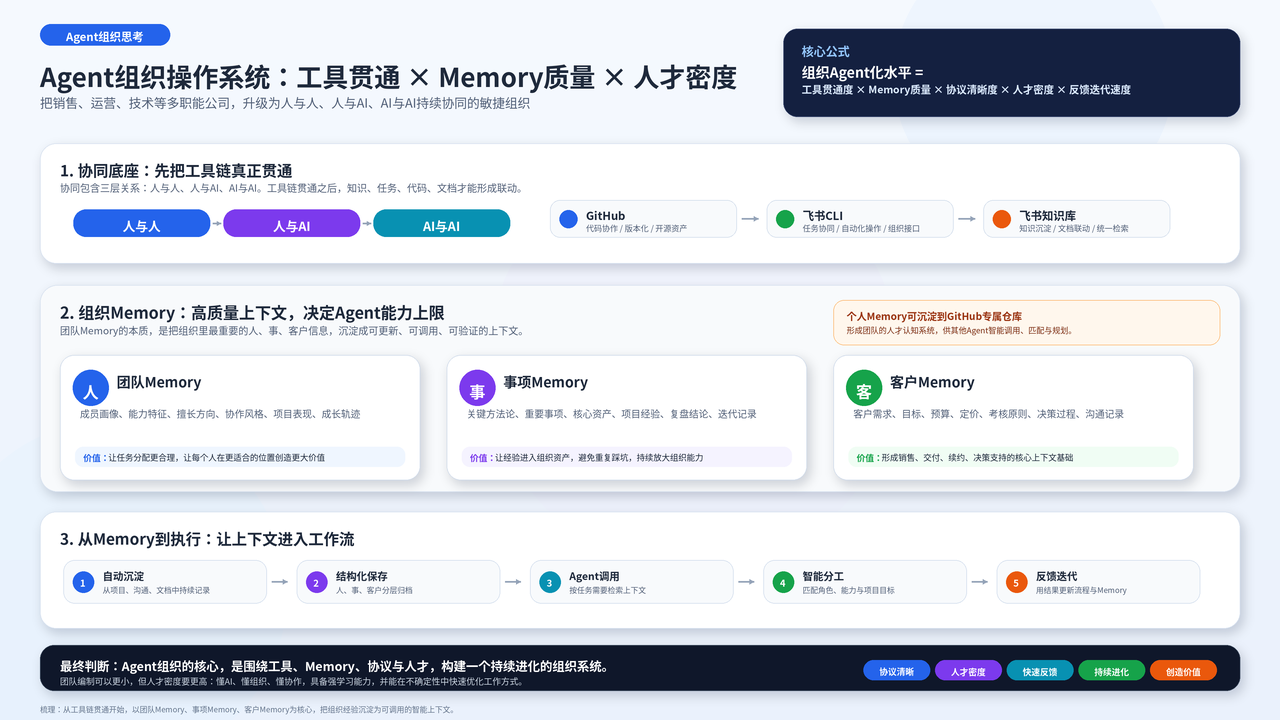
Recently I have been thinking about agent organizations.
For a company with functions such as sales, operations, and engineering, the first step toward building a truly agile agent organization is learning to use top-tier AI collaboration tools.
This collaboration has at least three layers: human to human, human to AI, and AI to AI.
GitHub remains one of the most important and mature pieces of infrastructure for this type of collaboration.
Beyond GitHub, teams also need to pay attention to another category of tools, such as Feishu CLI and the collaboration system around Feishu knowledge bases.
How should knowledge be captured with quality? How should it be stored in an orderly way? How should it connect with GitHub? How should knowledge, tasks, code, and documents become linked? These are all critical questions.
Only when the toolchain is truly connected can organizational collaboration efficiency keep improving.
At a deeper level, an agent organization must take team memory seriously. In essence, an AI organization’s capability depends on the quality of its organizational context.
Team memory first means memory about the team.
Each person’s strengths, preferences, capability profile, collaboration style, and performance across projects should gradually be recognized and accumulated.
Some people are better at data analysis. Some are better at user insight. Some are better at pushing complex collaboration forward. Some are better at abstracting methodology.
Only when the organization understands people clearly enough can it allocate work more reasonably and let each person create more value in a position that suits them, while also gaining a stronger sense of achievement.
On this basis, we can extend into personal memory.
Every team member can gradually form a personal memory and continuously deposit it into GitHub through some automation mechanism.
For example, a GitHub repository could dynamically record each person’s profile, capability traits, strengths, accumulated experience, collaboration preferences, and performance and growth across projects.
That repository would no longer be just a simple archive. It would gradually become the team’s talent cognition system.
More importantly, this personal memory system could connect with other agents and be intelligently called, matched, and planned in a scalable way. Then, when the organization allocates tasks, coordinates projects, combines capabilities, or plans roles, it will have a stronger intelligent foundation.
Second, there is memory about work.
This is about how to preserve important matters, key methods, core assets, and project experience so they can be updated, iterated, and turned into organizational capability.
Finally, there is customer memory.
Project information, customer needs, customer goals, budget amounts, target pricing, evaluation principles, key decision processes, and communication records all need to be systematically preserved.
These pieces of information become the core context of the agent organization. Whoever controls high-quality context is more likely to create efficient collaboration and decision-making.
Whether all this can work still depends on people.
Such a team can be smaller in headcount, but the requirements for each person are higher.
Team members need to understand AI, organization, and collaboration. They also need strong learning ability and the capacity to grow quickly.
They also need to embrace change, actively explore, and keep improving how they work under uncertainty.
The core of an agent organization is not only faster processes, fewer people, or more advanced tools. More importantly, it is whether the team can build a continuously evolving, collaborating, and value-creating organizational system around tools, memory, and human capability.
A simple formula:
Agentization level of an organization = tool connectivity x memory quality x protocol clarity x talent density x feedback iteration speed.